本文共 3188 字,大约阅读时间需要 10 分钟。
文章目录
布隆过滤器是什么?
布隆过滤器 (Bloom Filter) 是1970年由布隆提出的。
它实际上是一个很长的二进制向量和一些里随机映射函数。
布隆过滤器可以用来检索一个元素是否在一个集合中。
它的优点是空间效率和查询事件都比一般的算法要好得多,缺点是有一定的误识别率和删除困难。
基本概念
如果想要判读一个元素是不是存在一个集合中,一般想到的都是将所有元素保存起来,然后通过比较确定。链表、树等等数据结构都是这种思路,但是随着集合中元素的增加,我们需要的空间越来越大,检索速度也就越来越慢。
不过世界上还有一种叫做散列表(又称哈希表)的数据结构,它可以通过一个 Hash 函数将一个元素映射成一个位阵列 (Bit array) 中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了,这就是布隆过滤器的基本思想。
布隆过滤器就是专门用来解决去重问题的,使用布隆过滤器不会像使用缓存那么浪费空间,有优点,自然就有缺点,缺点就是不太精确。
我们可以使用 Bloom Filter 中的 pf.exists 方法去判断某一个值是否存在,这个判断不是很精确,判断某个值不存在,那就一定不存在,但是判断某个值存在,则有可能不存在。
Bloom Filter 的使用场景
布隆过滤器的使用可以减少磁盘 IO 或网络请求,只要判断一个值必然存在,就可以直接返回,不需要进行后续的请求。
- 在缓存穿透问题上,使用 Bloom Filter 判断数据是否存在,不存在直接返回
- 海量数据去重
Bloom Filter 的缺点
- 存在误判:可以根据业务的容忍度,控制误判率。
- 删除困难:一个放入布隆过滤器的元素映射到 bit 数组某个位置上都是1,删除的时候不能简单的直接将这些 bit 的位置设置为0,因为可能会影响到其它元素的判断。
- 布隆过滤器的不当使用有可能产生大 Value,增加 redis 的阻塞风险,生产环境建议体积庞大的布隆过滤器进行拆分。(大致思路:拆分成多个小 bit 集合,然后一个 key 的所有哈希函数必须都落在同一个 bit 集合上,不要分散在不同的 bit 集合上即可)
如何使用 Bloom Filter?
Bloom Filter 的安装
编译安装
// 安装 git 依赖yum install git// 拉取 Bloom Filtergit clone https://github.com/RedisBloom/RedisBloom.git// 进入拉取后的目录cd RedisBloom/// 编译make// 运行redis-server redis.conf --loadmodule /opt/redis-5.0.7/RedisBloom/redisbloom.so
安装完成,进入 redis-cli 中,执行 bf.add 命令,测试是否安装成功。
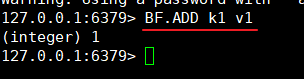
因为每次启动我们都要带很长的参数,可以在 redis.conf 配置文件中进行修改。
################################## MODULES ###################################### Load modules at startup. If the server is not able to load modules# it will abort. It is possible to use multiple loadmodule directives.## loadmodule /path/to/my_module.so# loadmodule /path/to/other_module.soloadmodule /opt/myredis/RedisBloom/redisbloom.so
最后一行就是我们要添加的地方,将我们自己的 redisbloom.so 文件所在目录配置进去即可,下次启动直接
redis-server redis.conf 即可 基本用法
常用命令分为两大类:添加元素和判断元素是否存在。
- bf.add\bf.madd 添加和批量添加
- bf.exists\bf.mexists 判断和批量判断值是否存在
Jedis 如何使用 Bloom Filter
首先添加依赖:
com.redislabs jrebloom 1.2.0
然后使用 jedis 测试:
public class BloomFilter { public static void main(String[] args) { GenericObjectPoolConfig config = new GenericObjectPoolConfig(); config.setMaxIdle(30); config.setMaxTotal(200); config.setMaxWaitMillis(30000); config.setTestOnBorrow(true); JedisPool jedisPool = new JedisPool(config,"192.168.253.100",6379,30000,"javaboy"); Client client = new Client(jedisPool); // 1.存入数据 for (int i = 0; i < 100000; i++) { client.add("name","javaboy-"+i); } // 2.检查数据是否存在 boolean exists = client.exists("name", "javaboy-999999"); System.out.println(exists); }} 默认情况下,Bloom Filter 的错误率是 0.01,默认的元素大小是 100,这两个参数也可以配置。
可以通过 bf.reserve 方法进行配置。(注意 name 必须是存在的 key)
BF.RESERVE name 0.0001 100000
第一个参数是 key,第二个参数是错误率,错误率越低,占用的空间就越大,第三个参数是预计存储的数量,当实际数量超出预计数量时,错误率会上升。
缓存击穿场景
比如在高并发的场景下,多线程同时查询同一个资源,如果缓存中没有这个资源,那么这些多线程就会去数据库中查找,对数据库造成极大压力,则缓存失去存在的意义。
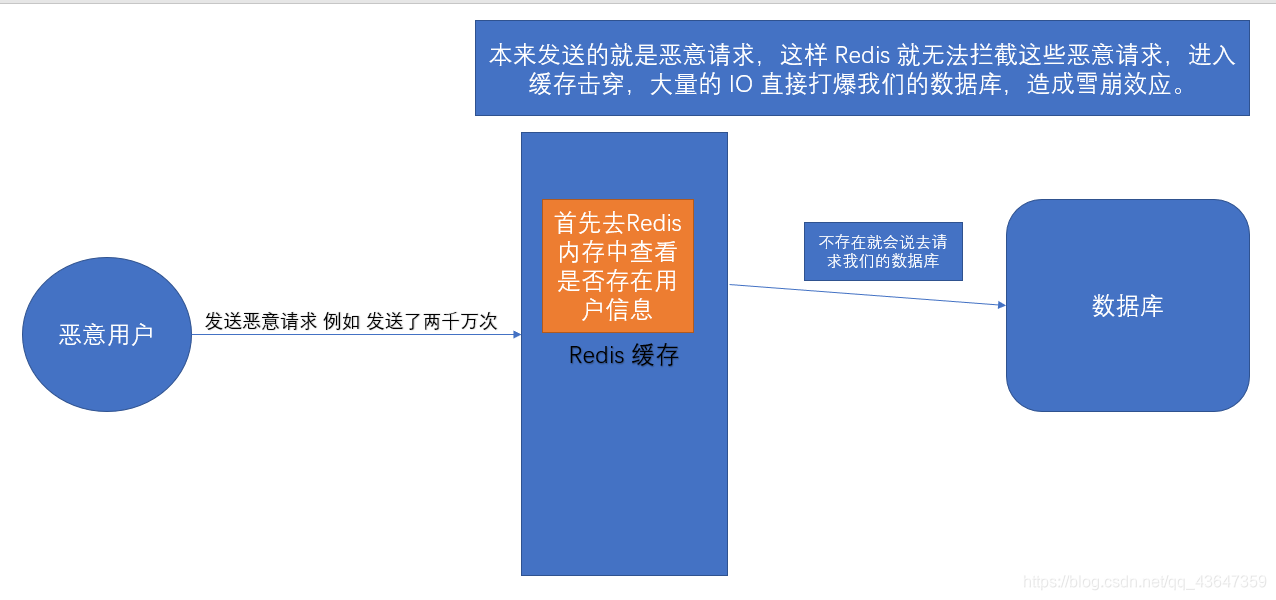
例如:现在有 1亿 条用户数据,现在要去数据库中查询,因为海量数据太大不仅效率极低而且数据库压力大,所有我们会把请求首先在 Redis 中进行处理(热点高频用户存在 Redis 中),Redis 中没有这个用户,再去数据库中查询。
现在可能会存在一种恶意请求,这些请求携带上了很多不存在的用户,首先请求会先去 Redis 中查看是否存在,Redis 中不存在就去数据库中查询,想象一下,忽然一下几千万的请求访问我们的数据库,数据库进而会直接被打崩,造成雪崩效应。
为了解决这个问题,我们就可以使用布隆过滤器,将 1亿 条用户存在布隆过滤器中,请求来了,先去布隆过滤器中寻找,如果存在,在去数据库中查询,否则就直接拒绝本次请求,至少通过布隆过滤器我们可以拒绝掉 99% 的恶意请求。
转载地址:http://wvqwi.baihongyu.com/